Requirements Gathering for Data Warehouse
Based on the size and complexity of the proposed approach, requirements gathering can be done using a number of different methods separately or in combination. However, the end result should be the same � a dimensional data model showing the logical structure of the database design, a process model showing the types of business activities which are to be supported and the view/form the information should take on the user�s desktop.
A D V E R T I S E M E N T
The types of activities that can be employed in requirements gathering include:
- Brainstorming
- Interviews
- Dimensional data modeling
- Process and context modeling
- Prototyping
- Story boarding
The sequence of how these techniques are applied is:
- Background materials and systems research and assessment.
- Brainstorming and/or interviewing.
- JAD which includes data and process modeling.
- Prototyping and revision of the data and process models.
Based on whatever analysis methods we choose, the focus here is to develop our understanding of what is required by:
- Establishing an understanding of the business (process modeling).
- Understanding how deep or detailed this analysis needs to be which will set the grain of our fact tables and surrounding dimensions (data modeling).
The data model provides:
- An understanding of the core business properties (dimensions).
- The essential knowledge to be analyzed (facts).
- The level of detail (the grain of the base fact tables).
- How core business objects need to be shared (conformed dimensions).
- The business meaning of each dimension, fact and data item.
- A user view of the data which can be immediately recognized and utilized by the business (the star schema model).
The process model provides:
- The canned or predictable processes required to access and format data for end-user consumption in terms of user views.
- The ad hoc process in accessing data at any level in the warehouse.
- The data quality audit processes in verifying data loading into the warehouse.
- The data access authorization (security) processes in governing access to the various levels of the data warehouse.
- The change and problem management processes required to support access to the data warehousing environment.
The basic mistake made is that much like in OLTP-systems analysis, process and data analysis are undertaken as separate and disjoint tasks. It is a crucial requirement that process and data modeling be done together. That is, we usually start with a context model or high-level view of the area of analysis. This model shows the major players and interfaces (source systems) which will feed our data warehouse. The next step is to drive out the essential business activities that form the candidate fact tables of our warehouse design. For example, in an insurance-based data warehouse, the processes being modeled may include fraud detection, claims processing, invoicing and collections. These four business activities may eventually form candidate fact tables called "fraud," "claim," "invoice" and "collection." Once these key business activities are understood in terms of focus, frequency and content, the corresponding dimensions can be identified and modeled as our star schema design. Once all the key business events have been identified, these can be cross-checked against the identified fact and dimension tables to be sure that all processes have a star schema model view defined for them and all stars that have been modeled actually will be accessed by a business activity as identified in our process analysis sessions. To allow this cross model validation to occur, the it is usually flipped back and forth between process and data analysis sessions with the user group until the completion of the analysis of the business activities included within scope and constrained by the context model which forms the "fence" for our analysis . Next, all process-centric star schema views are combined into one overall model which share the latest conformed dimensions across all the fact tables at the various levels of granularity which fall within our scope as illustrated in the figure below:
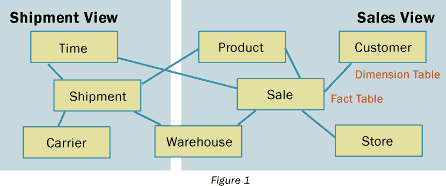
The user-view star models can also be used to understand what data sharing will be required by the various user groups and the degree of data sensitivity. The final step in our analysis is to confirm the levels of aggregation required to satisfy our requirements based on the types of analysis being done, the volume of data and the number of required levels of aggregation.
Business requirements analysis needs to provide the folowing information:
- Logical Modeling Steps
- The grain or level of granularity for each of the fact table (s).
- The number of conformed (cross-subject area) dimensions.
- Overall size for each dimension and fact table.
- Initial number and type of aggregates.
- The types and number of the predictable queries to be run against the model and their frequency.
- Currency and security regarding data for each dimension and fact.
- Validation in that each attribute in our model is referenced or used by a process object.
- A view into what will be required in terms of source system data to populate our model.
- The types of analytic tools to provide the users access to the information as contained in our model.
The first thing that the project team should engage in is gathering requirements from end users. Because end users are typically not familiar with the data warehousing process or concept, the help of the business sponsor is essential. Requirement gathering can happen as one-to-one meetings or as Joint Application Development (JAD) sessions, where multiple people are talking about the project scope in the same meeting.
It is also important for companies to make sure they data warehouses are
available 24 hours a day. In the past, data warehouses would be down for certain
periods of time, and this led to a lack of efficiency. Having the data
warehouses online 24 hours a day allows the company to be highly efficient.
In particular, end user reporting / analysis requirements are identified, and the project team will spend the remaining period of time trying to satisfy these requirements.
Associated with the identification of user requirements is a more concrete definition of other details such as hardware sizing information, training requirements, data source identification, and most importantly, a concrete project plan indicating the finishing date of the data warehousing project.
Based on the information gathered above, a disaster recovery plan needs to be developed so that the data warehousing system can recover from accidents that disable the system. Without an effective backup and restore strategy, the system will only last until the first major disaster, and, as many data warehousing DBA's will attest, this can happen very quickly after the project goes live.
Time Requirement : 2 - 8 weeks.
Deliverables :
-
A list of reports / cubes to be delivered to the end users by the end of this current phase.
-
A updated project plan that clearly identifies resource loads and milestone delivery dates.
Possible Pitfalls : This phase often turns out to be the most tricky phase of the data warehousing implementation. The reason is that because data warehousing by definition includes data from multiple sources spanning many different departments within the enterprise, there are often political battles that center on the willingness of information sharing. Even though a successful data warehouse benefits the enterprise, there are occasions where departments may not feel the same way. As a result of unwillingness of certain groups to release data or to participate in the data warehousing requirement definition, the data warehouse effort either never gets off the ground, or could not start in the direction originally defined.
When this happens, it would be ideal to have a strong business sponsor. If the sponsor is at the CXO level, she can often exert enough influence to make sure everyone cooperates.
|