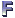Remember, a view is a virtual table - that is, it is only a
way of looking at the data in base tables, and it doesn't have any "real" data
of its own. Well, as I said, that was until recently - then someone got a much
better idea.
It probably deserves to be reiterated: Indexed Views are only supported by the
Enterprise, Developer, and Evaluation Editions of SQL Server. The other editions
(Standard and Personal) will allow you to create an index on a view (to avoid
syntax errors when migrating to one of the other editions), but the query
optimiser will not use the Indexed View in the query plan!
When a view is referred to, the logic in the query that makes up the view is
essentially incorporated into the calling query. Crucially, the calling query
just gets that much more complex. The extra overhead of figuring out the impact
of the view (and what data it represents) on the fly can actually get very high.
What's more, you're often adding additional joins into your query in the form of
the tables that are joined in the view.
Lamenting this issue often made me wish for a concept I made use of on the
AS/400 several years ago. The concept in question was referred to as a "join
file", and it essentially allowed multiple tables to have an index built over
them that was made up of data from all of participating tables. The "joined"
tables could effectively act as one without the normal overhead involved in
joining the tables - the index essentially made the relationship between the
tables a quick and easy access thing rather than a sort process every time a
query ran against the combined set of data.
I don't know who was the first to bring this concept to the RDBMS world, but
it's easy to say that Larry Ellison of Oracle was certainly the most vocal about
it. Around the time of the release of SQL Server 7.0, Mr. Ellison issued the
infamous "Million Dollar Challenge". The challenge was relatively simple -
Oracle would pay a million dollars to anyone who could show that SQL Server
could perform within 100 times the speed of Oracle on a particular query run on
a 1TB database that Oracle had constructed. This was, of course, one of those
contrived challenges meant to highly utilize a feature that Oracle had and SQL
Server didn't. The feature in question was something that Oracle refers to as a
"Materialized" view. Not surprisingly, the challenge was "closed" just a few
weeks before Microsoft demonstrated a system to meet the challenge.
For those readers who may be among the Oracle zealot crowd, please don't take
this as a knock on Oracle. They had a cool feature that SQL Server didn't have
an equivalent for. I'm not knocking that - in fact, I love it. The fact that one
product has something another doesn't (and usually vice versa) is simply great.
In the end, both products get better as they rush to try to both match and beat
each other. Frankly, I say "Go Oracle!" because it makes Oracle that much better
of a product, and, in addition, that invariably means that SQL Server is also
going to be spurred on to new heights.
SQL Server now has something that is, in many ways, equivalent to Oracle's
Materialized View from a user standpoint. An Indexed View is essentially a view
that has had a set of unique values "materialized" into the form of a clustered
index. The advantage of this is that it provides a very quick lookup in terms of
pulling the information behind a view together. After the first index (which
must be a clustered index against a unique set of values), SQL Server can also
build additional indexes on the view using the cluster key from the first index
as a reference point. That said, nothing comes for free - there are some
restrictions about when you can and can't build indexes on views (I hope you're
ready for this one - it's an awfully long list!):
- The view must use the SCHEMABINDING option
- If it references any User Defined Functions (more on these in Chapter
13), then these must also be schema bound
- The view must not reference any other views - just tables and UDFs
- All tables and UDFs referenced in the view must utilize a two part (not
even three part and four part names are allowed) naming convention (for
example dbo.Customers, BillyBob.SomeUDF) and must also have the same owner
as the view
- The view must be in the same database as all objects referenced by the
view
- The ARITHABORT option must be turned on (using the SET command) at the
time the index is created
To create an example Indexed View, let's start by making a
few alterations to the CustomerOrders_vw object that we created earlier in the
chapter:
ALTER VIEW CustomerOrders_vw
WITH SCHEMABINDING
AS
SELECT cu.CompanyName,
o.OrderID,
o.OrderDate,
od.ProductID,
p.ProductName,
od.Quantity,
od.UnitPrice
FROM dbo.Customers AS cu
INNER JOIN dbo.Orders AS o
ON cu.CustomerID = o.CustomerID
INNER JOIN dbo.[Order Details] AS od
ON o.OrderID = od.OrderID
INNER JOIN dbo.Products AS p
ON od.ProductID = p.ProductID
The big things to notice here are:
- We had to make our view use the SCHEMABINDING option
- In order to utilize the SCHEMABINDING option, we had to go to two part
naming for the objects (in this case, all tables) that we reference
We had to remove our calculated column - while you can build
indexed views with non-aggregate expressions, the query optimiser will ignore
them. The only way to utilize such a view is by using a direct query hint (we
will learn more about optimiser hints in Chapter 17).
This is really just the beginning - we don't have an indexed view as yet.
Instead, what we have is a view that can be indexed. When we create the index,
the first index created on the view must be both clustered and unique.
SET ARITHABORT ON
CREATE UNIQUE CLUSTERED INDEX ivCustomerOrders
ON CustomerOrders_vw(CompanyName, OrderID, ProductID)
Once this command has executed, we have a clustered view. We
also, however, have a small problem that will become clear in just a moment.
Let's test our view by running a simple SELECT against it:
SELECT * FROM CustomerOrders_vw
If you execute this, everything appears to be fine - but try
displaying the graphical showplan (Display Estimated Execution Plan is the tool
tip for this, and you'll find it towards the right-hand side of the toolbar):
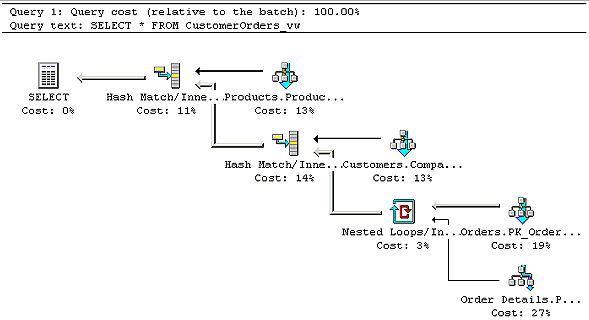
I mentioned a paragraph or two ago that we had a small problem - the evidence is
in this showplan. If you look through all the parts of this, you'll see that our
index isn't being used at all!
At issue here is the size of our tables. The Northwind database doesn't have
enough data. You see, the optimiser runs a balance between how long it will take
to run the first plan that it finds versus the amount of work it takes to keep
looking for a better plan. For example, does it make sense to spend two more
seconds thinking about the plan when the plan you already know about could be
done in less than one second?
In our example above, SQL Server looks at the underlying table, sees that there
really isn't that much data out there, and decides that the plan it has is "good
enough" before the optimiser gets far enough to see that the index on the view
might be faster.
Keep this issue of "just how much data is there" versus "what will it cost to
keep looking for a better plan" in mind when deciding on any index - not just
indexed views. For small datasets, there's a very high possibility that SQL
Server will totally ignore your index in favor of the first plan that it comes
upon. In such a case, you pay the cost of maintaining the index (slower INSERT,
UPDATE, and DELETE executions) without any benefit in the SELECT.
Just so we get a chance to see a difference, however, let's create a database
that will have enough data to make our index more interesting. You can download
and execute a population script called CreateAndLoadNorthwindBulk.sql.
Figure that, if you load the default amount of data, you're going to use up
somewhere in the area of 55MB of disk space for NorthwindBulk. Also, be aware
that the population script can take a while to run, as it has to generate and
load thousands and thousands of rows of data.
Now just recreate your view and index in your new NorthwindBulk database.
USE NorthwindBulk
GO
CREATE VIEW CustomerOrders_vw
WITH SCHEMABINDING
AS
SELECT cu.CompanyName,
o.OrderID,
o.OrderDate,
od.ProductID,
p.ProductName,
od.Quantity,
od.UnitPrice
FROM dbo.Customers AS cu
INNER JOIN dbo.Orders AS o
ON cu.CustomerID = o.CustomerID
INNER JOIN dbo.[Order Details] AS od
ON o.OrderID = od.OrderID
INNER JOIN dbo.Products AS p
ON od.ProductID = p.ProductID
GO
SET ARITHABORT ON
CREATE UNIQUE CLUSTERED INDEX ivCustomerOrders
ON CustomerOrders_vw(CompanyName, OrderID, ProductID)
Now re-run the original query, only against NorthwindBulk:
USE NorthwindBulk
SELECT * FROM CustomerOrders_vw
And check out your new queryplan:
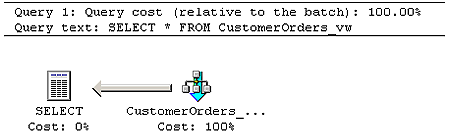
This time, SQL Server has enough data that it does a more thorough query plan.
In this case, it accepts the index view that exists on our table. The overall
performance of this view is now much faster (row for row) than the previous
model would have been.
OK Folks! One more time (just in case)! If you're using the Standard or Personal
Editions of SQL Server 2000, you will still see the old query plan here! The
query optimizer in those editions will not make use of the new index - if you
want to see this example work, you have to be using the Enterprise, Evaluation,
or Developer Edition.