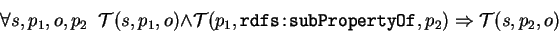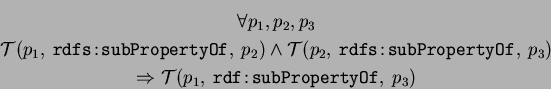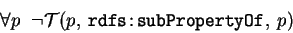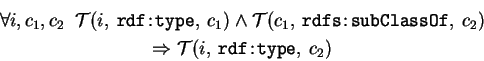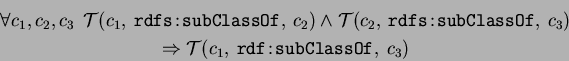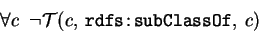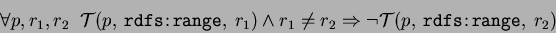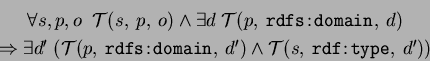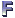We can distinguish three kinds of concepts in the RDF:
A D V E R T I S E M E N T
The fundamental concepts, The
schema-definition concepts (useful for defining a new vocabularies) and The utility concepts
(are the concepts which are not absolutely necessary, but are likely to be useful in any of
the application domain).
The Fundamental concepts
RDF Resource
RDF is about describing the resources; according to the
"resources are always named by URIs" and "anything can have URI".
So an RDF can theoretically be used to describe anything. Yet it mainly designed
to handle "network retrievable" resources.
[] underlines that "the resource is conceptual mapping to an entity (...), not
necessary that the entity which corresponds to this mapping at any particular instance
of time". However most of the time we are interested in the entities themselves. It is
therefore important to note that meta-data we express about resources may require the
different levels of interpretation, that may be valid in certain context only.
For example, URI http://www.w3.org/Icons/WWW/w3c_main returns W3C logo in a
PNG or GIF format, depending on the browser being used. Another example is daily
weather report, whose URL would return a different page each day.
It follows that interpretation of the resources (and therefore of the RDF triples) is highly
contextual. We can define the notion of a stable resource as follows: The stability for the
resource is a property of being the same in any context, from the user (or community of users)
point of view. This definition is still very contextual: it is dependant on the users we are
considering, more precisely on the task which they need to accomplish.
Consider for an example, from a standard reader point of view of, the W3C logo is stable,
since GIF and PNG versions look the same, but a weather report is not stable. On the
other hand, someone interested in image formats only may consider W3C logo unstable
and weather report stable -- assuming a weather report as always generating images
in a same format.
However, in most of the applications, task is less likely to change than retrieving
context, thus the stability assumption might be valuable.
RDF Property
Properties are the resources used as predicate of the triples; semantics of a triple
clearly depends on a property used as predicate. Two things are very important with
this concept of property:
Firstly, The RDF considers properties as the first class object, unlike most of the object
modeling languages, where the properties are the attributes of a class. Even if the
concept of the class exists in the RDF, properties can be defined and used independently of
the classes. .
Secondly, as it has been mentioned, the fact that properties are the
resources allows to describe them with the RDF itself. This will be widely used by
the following concepts.
RDF Statement
A statement is a resource reifying the triple. Such a resource must have atleast three
properties : the RDF:subject, the RDF :object and RDF:predicate, valued by
corresponding resources.
The reification of the triples may seem a utility concept rather than the fundamental
concept. Nevertheless it is defined as the part of model in a W3C recommendation. This
will support the will to use the RDF as its own meta-system, to make every element of
the RDF describable in RDF itself.
The Schema definition concepts
In the schemas, new resources can be defined as specialization of the old ones, thus
allowing to infer implicit triples. Schemas also constrains the context in which the
defined resources can be used, inducing the notion of the schema validity. We will see
that those two notions can be seen as one, in a point of view based on the first-order
logic. They all can be expressed as the rules allowing to infer new facts (basically,
the new triples or negations of the triples). In these rules, the 3-ary logical
predicate will be used to represent the believed triple.
RDFS:subPropertyOf
Any of the property denotes the relation between resources (the set of a resource couples
linked by the arc labeled with a property). RDFS:subPropertyOf applies to the properties
and must be interpreted as a subset relation between the relation which they denote. Thus
the following rule does stand:
For example, if the "mother" is sub-property of "parent", any triple having the "mother"
as predicate should also be considered as having "parent" as the predicate. This property
is very important in the schema definitions for the interoperability between the RDF agents.
In the example above, the agent not knowing the semantics of "mother" could at least treat
it as the "parent" (assuming it knows semantics of the "parent").
Since the RDFS:subPropertyOf denotes a subset relation, the transitivity
rule also do stand:
Note that it is considered invalid to have the cycles in RDFS:subPropertyOf,
though it does not define the way to express this constraint in the RDF4. Anyway, the
corresponding logical rule is the following (since any of the cycle would result, with
the transitivity, in a property being its own sub-property):
Note that there is no standard URI for an universal property (super-property
of any of the property).
RDFS:Class, rdf:type and the RDFS:subClassOf
Classes are the resources denoting a set of the resources, by the means of the property
RDF:type (instances that have the property RDF:type valued by a class). Since all the sets
of resources presented in this section are resources (they have an URI), by definition
they do have the property RDF:type valued by the RDFS:Class. On the other hand, all the
properties (defined in the W3C recommendation or in any schema) have RDF:type valued by
RDF:Property.
Classes are structured in the same way as the properties, in a subset hierarchy denoted by
the property RDFS:subClassOf. As for RDFS:subPropertyOf, cycles should not exist though
it can be used to express the equivalence, but contrary to property hierarchy, the
class hierarchy has the maximum element: it is of course the RDF:Resource (so any class
can implicitly has the RDFS:subClassOf valued by the RDFS:Resource). The following rules,
similar to the rules related to the RDFS:subPropertyOf, do stand:
RDFS:domain and RDFS:range
These properties do apply to the properties and must be valued by the classes. They are
used to restrict a set of resources that may have the given property (the property's
domain) and the set of valid values for the property (its range). A property may have
as many values for the RDFS:domain as needed, but no more than one value for the RDFS:range
For the triple to be valid, object must match the range (if any) of predicate
(that is, it should have the RDF:type valued by corresponding class or one of its
subclasses), and the subject should match at least one of the domains (if any) of the
predicate (Note that if the predicate has the super-properties, this should also be
checked recursively for all of them). This can logically bne expressed by:
It is worth noting that, though this two rules are intended to be used for the validity
checking only, and the first one (RDFS:domain rule) can actually be used only this way
(it cannot be used to perform the inference since its consequence is existentially
qualified), the second one (RDFS:range rule) has different interpretations depending on the
hypothesizing closed or open world. In a closed world hypothesis, any missing
triple is considered negated, so a RDFS:range rule has only to be verified. But in
the open world hypothesis, missing triples are not necessarily to be false, so the rule
can be used to perform the inference instead. Since the "natural" field of the RDF is
web, where the information is by essence distributed and incomplete, the open world
hypothesis seems to be much more reasonable.
RDFS:Literal
A resource rdfs:Literal, denoting the set of literals, declared as the
class (though literals are not the resources, according to recommendation!). Its
intended use is to be a range of properties.
The Utility concepts
These concepts might have been defined in the external schemas, but since they are of
common use, they have been defined once for all in a core schema.
RDFS:Container
Containers are the collection of resources. They are modeled by the instance of one of
the three subclasses of RDFS:Container: the RDF:Bag ( unordered collection ), RDF:Seq
( ordered collection ) or RDF:Alt ( an alternative ). Membership is modeled by the
automatically generated properties RDF:_ 1, RDF:_ 2, etc. These properties are the
instances of RDFS:ContainerMembershipProperty, a subclass of RDF:Property5.
RDFS:ConstraintResource and RDFS:ConstraintProperty
It can be interesting for the RDF agent to be informed of an unknown resource
(or more specifically the property) is defining the validity constraint. The set of such
resources is RDFS:ConstraintResource. Its subclass RDFS:ConstraintProperty is of
course the subclass of RDF:Property too. The Properties RDFS:domain and RDFS:range defined
above are the instances of RDFS:ConstraintProperty.
RDFS:seeAlso and RDFS:isDefinedBy
A given resource might have be described in more than one place over the internet. The
RDFS:seeAlso property can be used to point out the alternative descriptions of the subject
resource. Its sub-property RDFS:isDefinedBy more specifically points to the original or
authoritative description.
RDFS:label and RDFS:comment
It could be useful to describe the resource with human readable text in addition
to the "pure" RDF properties; this is the role of RDFS:label and RDFS:comment. The
former is used to give the human-readable name of a resource, the latter, to give the
longer description. Note that they can have the multiple values for internationalization
needs.