More about CORBA
A D V E R T I S E M E N T
Let's move our discussion of CORBA from the past to the future. We have discussed much of the fundamental aspects of CORBA programming and there are many more details to cover before we can begin to say that we have our arms around the core functionality of CORBA or the CORBA Services. The problem with this comprehensive functionality is the high level of complexity -- which scares many people away from developing in the CORBA environment. An interesting aspect of developing distributed applications is that most developers are interested in trying to provide or acquire many of the same underlying services. These underlying services include security, event notification, persistence and transactions. And they are critical for giving your distributed application long-term value. The question we need to have answered is: How can these services be packaged so that they are easy to use, easy to learn and easy to distribute?
The specification for the CORBA Component Model (CCM) is written to address these and other complexities in the CORBA object model. The CCM is part of the CORBA 3.0 specification, which is due to be released this year. The CCM is a server-side component model for building and deploying CORBA applications. It is very similar to Enterprise Java Beans (EJB) because it uses accepted design patterns and facilitates their usage, enabling a large amounts of code to be generated. This also allows system services to be implemented by the container provider rather than the application developer. The benefit and need for these types of containers can be observed through the growth of Application Server software. The CCM extends the CORBA object model by defining features and services in a standard environment that enable application developers to implement, manage, configure and deploy components that integrate with commonly used CORBA Services. These server-side services include transactions, security, persistence, and events.
common data representation (CDR)
format to transfer data across the network.
An object reference does not describe the interface of an object. Before
an application can make use of an object (reference), it must somehow
determine/know what services an object provides.
Interfaces to objects are defined via the
Interface Description Language (IDL). The OMG IDL defines the
interface of an object by means of the various methods they support and the
parameters these methods accept. Various language mappings exist for the IDL
(for example, C, C++, Java, COBOL, etc.). The generated language stubs
provide the application with compile-time knowledge which allows these
interfaces to be accessed.
The interfaces, alternatively, can be added to a special database, called
the interface repository. The
interface repository contains a dynamic copy of the interface information of
an object, which is generated statically via the IDL. The
Dynamic Invocation Interface (DII) is
the facility by which an object client can probe an object for the methods
it supports and, upon discovering a particular method, can invoke it at
runtime. This involves looking up the object interface, generating the
method parameters, invoking the method on the remote object and returning
the results.
On the �server� side, the Dynamic Skeleton
Interface (DSI) allows the ORB to invoke object implementations
that do not have static (i.e., compile time) knowledge of the type of object
it is implementing. All requests to a particular object are handled by
having the ORB invoke the same single call-up routine, called the
Dynamic Interface Routine (DIR). The
Implementation Repository (as opposed
to Interface Repository) is a runtime database of information about the
classes the ORB knows of, its instantiated objects and additional
implementation information (logging, security auditing, etc.).
The Object Adapter sits above the core ORB network functionality. It acts
as a mediator between the ORB and the object, accepting method requests on
the object's behalf. It helps alleviate �bloated� objects or ORBs.
The Object Adapter enables the instantiation of new objects, requests
passing between the ORB and an object, the assignment of object references
to an object (uniquely naming the object), and the registering of classes of
objects with the Implementation Repository.
Currently, all ORB implementations must support one object adapter, the
Basic Object Adapter (BOA).
All of this talk about interoperability is not useful unless ORBs from
different developers/vendors can communicate with one another. The
General InterORB Protocol (GIOP) is a
bridge specifying a standard transfer syntax and a set of message formats
for the networking of ORBs. The GIOP is independent of any network
transport.
The Internet InterORB Protocol (IIOP)
specifies a mapping between GIOP and TCP/IP. That is, it details how GIOP
information is exchanged using TCP/IP connections. In this way, it enables
�out-of-the-box� interoperability with IIOP-compatible ORBs based on the
world's most popular product and vendor neutral network transport�TCP/IP.
Multi-tier Network Computing
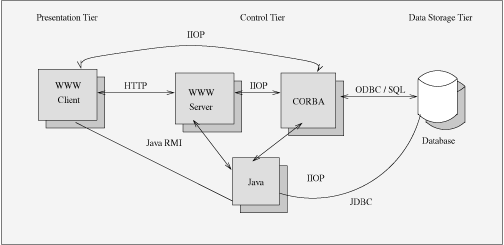
CORBA is an example of what is termed �middleware�--a technology that
enables the separation of applications into three distinct sections (see
Figure 5):
- The presentation, or user interface, tier
- The business logic, or control, tier
- The data storage tier
Figure 5. Three-Tier Network Computing
|